April 21, 2026 An open-source project called OpenMythos has proposed a detailed, code-level reconstruction of the unpublished “Claude Mythos” model architecture, offering a falsifiable hypothesis rather than a summary or approximation. The project’s central claim is that “Claude Mythos,” associated with Anthropic, may be built as a Recurrent-Depth Transformer, where reasoning depth scales through iterative computation at inference time instead of increasing parameter count.
Developed from first principles and grounded in existing research, the project frames its design as a specific, testable claim about how Anthropic might structure advanced models. Unlike conventional transformers such as GPT or LLaMA, which pass inputs through a fixed stack of unique layers, the proposed architecture reuses the same weights across multiple iterations within a single forward pass.
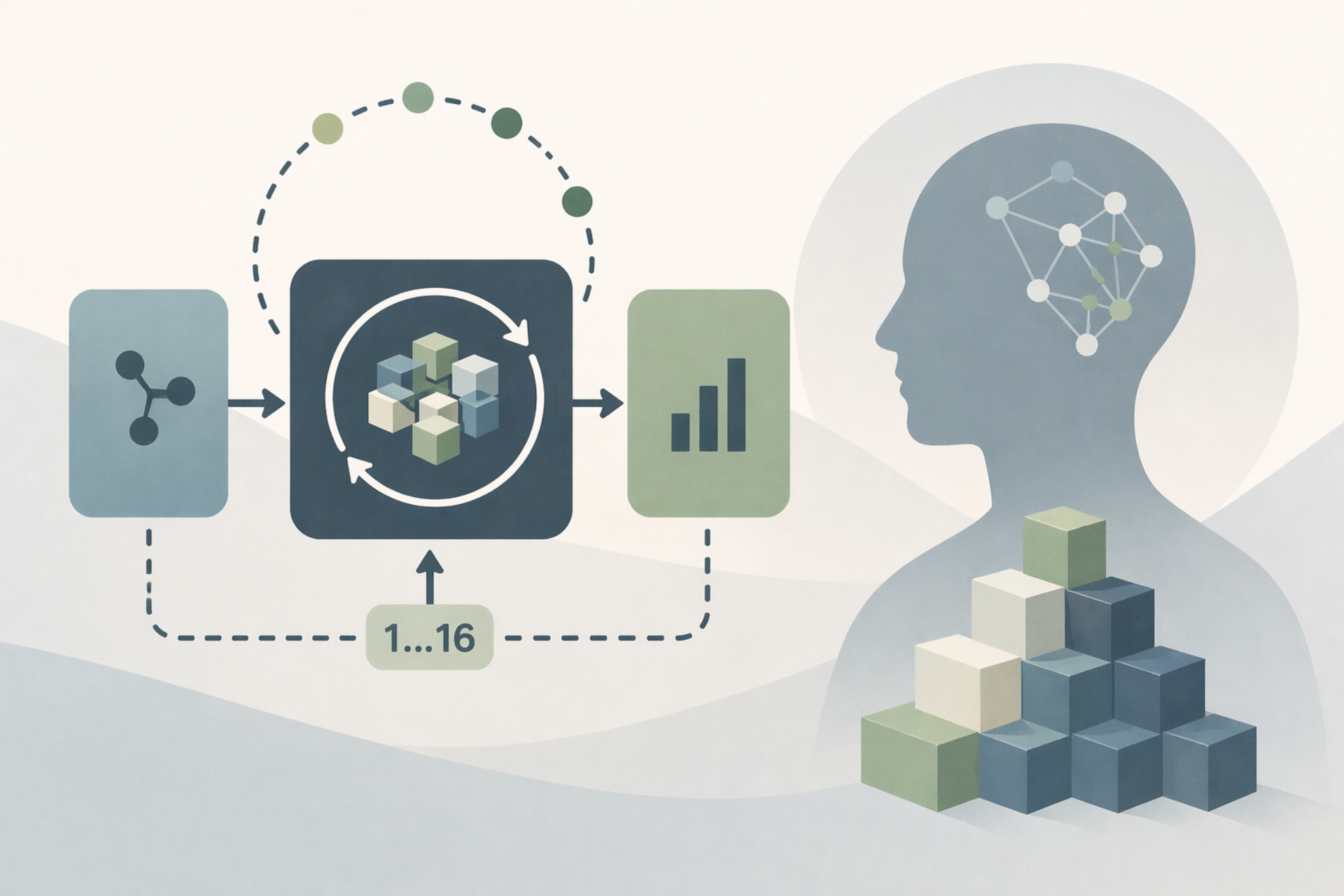
OpenMythos structures this as a three-part pipeline: Prelude → Recurrent Block → Coda. The Prelude and Coda run once, while the Recurrent Block loops up to 16 times, updating a hidden state by combining prior state, re-injected input, and a transformer operation. This re-injection ensures the model does not drift away from the original prompt during deep iterative reasoning.
Within the loop, the architecture replaces standard feedforward layers with a Mixture-of-Experts design based on DeepSeekMoE. Only a subset of experts is activated per token, and the routing mechanism selects different experts at each iteration. This makes each loop computationally distinct while keeping the base parameters fixed, separating reasoning depth from model size.
Attention is handled using a compressed key-value approach similar to DeepSeek-V2, reducing memory requirements by an estimated 10–20× at scale. The design also keeps reasoning entirely in continuous latent space, rather than generating intermediate tokens. Each iteration effectively acts as a reasoning step, enabling the model to extend its reasoning chain by increasing loop depth at inference time.
The approach introduces both flexibility and complexity. A Recurrent-Depth Transformer can handle longer reasoning tasks without retraining by simply running more iterations. Harder problems receive more compute, while simpler ones can halt early. This differs from standard models, which are constrained by the reasoning depth seen during training.
To address stability issues common in looped systems, OpenMythos applies constraints derived from the Parcae architecture, ensuring the hidden state remains bounded across iterations. It also uses Adaptive Computation Time to determine when to stop looping, avoiding degradation from excessive computation. Depth-wise LoRA adapters add slight variation across iterations without significantly increasing parameters.
Research cited in the project suggests this approach can be more parameter-efficient. A 770 million parameter Recurrent-Depth Transformer has been shown to match a 1.3 billion parameter standard transformer on the same data, indicating that reasoning capability may scale with inference-time compute rather than stored weights.

